In SAS, there are multiple ways to calculate overall rank or rank by a grouping variable. In data step, it can be done via RETAIN statement. SAS made it easy to compute rank with PROC RANK.
Create Sample Data
The following SAS program creates a dataset which will be used to explain examples in this tutorial.
data temp;
input ID Gender $ Score;
cards;
1 M 33
2 M 94
3 M 66
4 M 46
5 F 92
6 F 95
7 F 18
8 F 11
;
run;
How to Compute Rank of a Variable
n the following SAS Program, we are calculating the rank of the variable “Score”.
proc rank data= temp out = result;
var Score;
ranks ranking;
run;
Notes :
- The OUT option is used to store output of the rank procedure.
- The VAR option is used to specify numeric variable (s) for which you want to calculate rank
- The RANKS option tells SAS to name the rank variable
- By default, it calculates rank in ascending order.
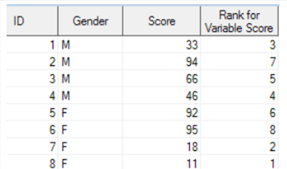
Reverse order of ranking (Descending):
Suppose you need to assign the largest value of a variable as rank 1 and the last rank to the lowest value. The descending keyword tells SAS to sort the data in descending order and assign rank to the variable accordingly.
proc rank data= temp descending out = result;
var Score;
ranks ranking;
run;
Percentile Ranking
Suppose you need to split the variable into four parts, you can use the groups option in PROC RANK. It means you are telling SAS to assign only 4 ranks to a variable.
proc rank data= temp descending groups = 4 out = result;
var Score;
ranks ranking;
run;
Use GROUPS=4 for quartile ranks, and GROUPS=10 for decile ranks, GROUPS = 100 for percentile ranks.
Ranking by Group
Suppose you need to calculate rank by a grouping variable (Gender). To accomplish this task, you can use the by statement in proc rank. Please note that it is required to sort the data before using by statement.
proc sort data = temp;
by gender;
run;
proc rank data= temp descending out = result;
var Score;
ranks ranking;
by Gender;
run;
How to Handle Ties When Ranking
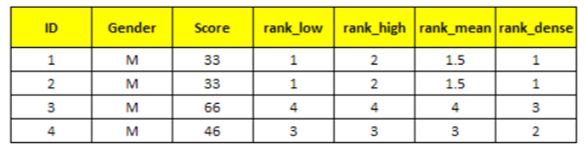
Let’s create a sample dataset. See the variable “score” having same values (33 appearing twice).
data temp2;
input ID Gender $ Score;
cards;
1 M 33
2 M 33
3 M 66
4 M 46;
run;
To handle duplicate values in ranking, you can use option TIES = HIGH | LOW | MEAN | DENSE in PROC RANK.
See the comparison between these options in the image below
proc rank data= temp2 ties = dense out = result;
var Score;
ranks rank_dense;
run;
- LOW – assigns the smallest of the corresponding ranks.
- HIGH – assigns the largest of the corresponding ranks.
- MEAN – assigns the mean of the corresponding ranks (Default Option).
- DENSE – assigns the smallest of the corresponding rank and add +1 to the next rank (don’t break sequence)