Inner Join
The INNER JOIN returns rows common to both tables (data sets). If we select * keyword in the query, the final merged file would have number of columns equal to (Common columns in both the data sets + uncommon columns from data set A + uncommon columns from data set B).

data A;
input ID name$ height;
cards;
1 A 1
3 B 2
5 C 2
7 D 2
9 E 2
;
run;
Data b;
input ID name$ weight;
cards;
2 A 2
4 B 3
5 C 4
7 D 5
;
run;
proc print;
run;
PROC SQL;
Create table myjoi as
Select * from A as x, B as y
where x.ID = y.ID;
Quit;
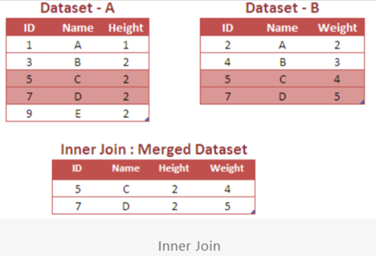
Since the above case is of type INNER JOIN, it returns values 5 and 7 from the variable ID in the combined table as these two values are common in both the datasets A and B
Another way to write the above code –
PROC SQL;
Create table dummy as
Select * from A as x inner join B as y
On x.ID = y.ID;
Quit;
Left Join
The LEFT JOIN returns all rows from the left table with the matching rows from the right table.

PROC SQL;
Create table om1 as
Select * from A as x left join B as y
On x.ID = y.ID;
quit;
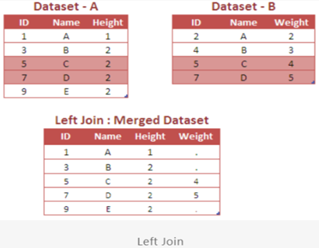
Since the above case is of type LEFT JOIN, it returns all rows from the table (dataset) A with the matching rows from the dataset B.
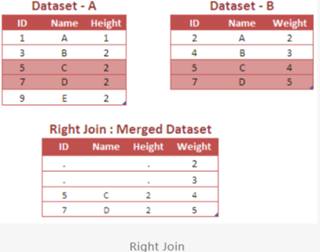
Right Join
The RIGHT JOIN returns all rows from the right table that do not match any row with the left-hand table, and the matched rows from the left-hand table.

proc sql;
create table om1 as
select * from A as x right join B as y
on x.id=y.id;
quit;
proc print;
run;
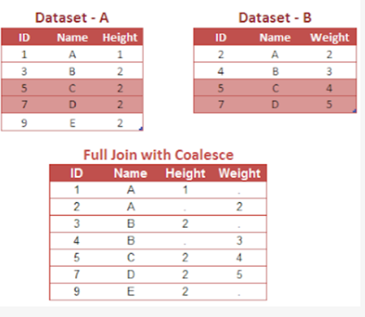
Full Join
The FULL JOIN returns all rows from the left table and from the right table.
Key takeaway : The FULL JOIN suffers the same difficulty as the RIGHT JOIN. Namely, the common variable values are lost from the right-hand data set. The COALESCE function can solve this difficulty.
proc sql;
create table om1 as
select * from A as x full join B as y
on x.id=y.id;
quit;
proc print;
run;
Cross Join / Cartesian product(vertically join)
The Cartesian product returns a number of rows equal to the product of all rows (observations) in all the tables (data sets) being joined. For example, if the first table has 10 rows and the second table has 10 rows, there will be 100 rows (10 * 10) in the merged table (data set).
proc sql;
create table om3 as
select * from A as x cross join B as y;
quit;
proc print;
run;
Key takeaways
- Since the first data set has 5 rows and the second data set has 4 rows, there are 20 rows (5 * 4) in the merged data set.
- The ‘as’ keyword (aka alias) is used to assign a table a temporary name.
- Since the ID values of the first data set is different than the ID values of the second data set, the ID given in the joined data set is misleading.
UNION in PROC SQL The following SAS program creates datasets that will be used to explain examples in this tutorial

data datasetA;
input product $ sales;
cards;
A 60
A 65
B 36
C 78
D 91
;
run;
data datasetB;
input product $ profit;
cards;
A 62
A 62
D 23
E 25
F 32
G 41
;
run;
The UNION operator within PROC SQL is used to combine datasets by rows in SAS. It does not allow duplicate records in the concatenated dataset.
proc sql;
create table newData as
select * from datasetA
UNION
select * from datasetB;
quit;
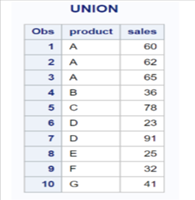
UNION operator combines datasets vertically based on column position rather than column name.
UNION ALL
The ALL keyword keeps the duplicate rows. It is also efficient than the UNION operator as it does not execute the step of removing duplicates.

INTERSECT Operator in PROC SQL:
This tutorial explains how to use the INTERSECT operator in PROC SQL in SAS, along with examples.
In PROC SQL, the INTERSECT operator is used to find the common records that exist in tables. The basic syntax of INTERSECT OPERATOR within PROC SQL is as follows :
PROC SQL;
SELECT *
FROM dataset1
INTERSECT
SELECT *
FROM dataset2;
QUIT;
The following programs creates two sample SAS datasets that will be used to explain examples in this tutorial.
data dataset1;
input ID Name $;
datalines;
1 Dave
2 Mario
3 Steve
;
run;
data dataset2;
input ID Name $;
datalines;
1 Dave
2 Steve
4 Priya
;
run;
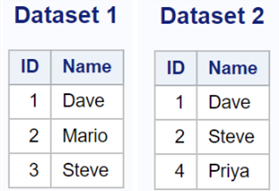
In this case, it stores the common records of both tables into a new dataset named ‘outdata’.
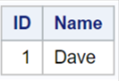
PROC SQL;
CREATE TABLE outdata as
SELECT *
FROM dataset1
INTERSECT
SELECT *
FROM dataset2;
QUIT;
EXCEPT Operator in PROC SQL
The following SAS program creates datasets that will be used to explain examples in this tutorial.
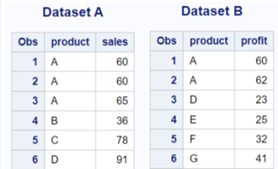
data datasetA;
input product $ sales;
cards;
A 60
A 60
A 65
B 36
C 78
D 91
;
run;
data datasetB;
input product $ profit;
cards;
A 60
A 62
D 23
E 25
F 32
G 41
;
run;
The EXCEPT operator within PROC SQL is used to find unique rows from the first table that are not found in the second table.
proc sql;
create table outData as
select * from datasetA
EXCEPT
select * from datasetB;
quit;
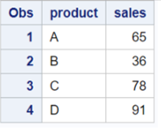
EXCEPT ALL:
The ALL keyword keeps the duplicate records.

proc sql;
create table outData as
select * from datasetA
EXCEPT ALL
select * from datasetB;
quit;
you may have noticed that EXCEPT ALL returned 5 rows in the output dataset, whereas the EXCEPT operator returned 4 rows.